CSVやJSONのデータを手軽に整形できるコマンドラインツール「Miller」ガイド
Miller は、CSV、TSV、JSONなど、さまざまな形式のデータ ファイルを操作、整形、および再フォーマットするためのコマンドラインツールです。
データ整形に使えるコマンドツールとしてはawkやjqなどがありますが、Miller はデータ分析に必要な前処理(データクリーニング、データ削減/フィルタリング、フォーマットの変換)を手軽に行えるように設計されています。
また、日時(文字列)の値をDate型に変換して処理することができるため、時系列データを簡単に整形したりフィルタリングすることができます。
表形式データなどkey-value-pairsのリストデータをコマンドラインで操作したいときにとても便利なツールなのでお勧めです。
■インストール
millerのインストール方法については「Installing Miller」ページを参照してください。
Linuxであればyumやapt、Macであればbrew、windowsならchocoなどのパッケージ管理ツールでインストールすることができます。
ただしwindowsの場合、文字コードの関係でコマンドプロンプトやデフォルト設定のPowerShellで使うのは難しいかもしれません。
そのため、windowsの場合はWSLで使用するのをお勧めします。
なお、wsl(Ubuntu)にaptでインストールしてみたところ、バージョンが古いのか公式ドキュメントにのっているverbでも使えないものがいくつかありました。
■mlrコマンドの基本形式
millerのコマンド名は「mlr」で、基本的な書式は以下となります。
|
1 |
$ mlr [入力/出力を指定するオプション] [verb(動詞)] [verbのオプション] [ファイル名] |
verb(ヴァーブ)は、mlrコマンドで行う処理を指定する箇所になります。
データをフィルタリングするのか、ソートするのか、結合するのか、あるいは集計するのかなどをヴァーブで指定します。
-lオプションでヴァーブの一覧を取得できます。
|
1 |
$ mlr -l |

|
1 |
$ mlr <verb> --help |
■サンプルデータ
記事で使用したサンプルデータは以下に置いてあります。
■ファイルの入力・出力
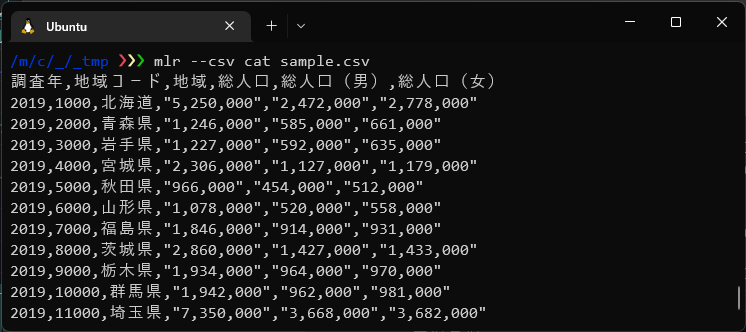
・csvファイルを読み込み、そのまま出力する
|
1 |
$ mlr --csv cat sample.csv |
–csvオプションで入出力のファイル形式を指定しcatヴァーブ(verb)で標準出力を指定しています。
ヴァーブをつけないと何も出力されずエラーになるので注意してください。

csvの他にも–jsonでjson形式のファイルを、–tsvでtsv形式のファイルを読み込むことができます。
・出力する行数を指定する
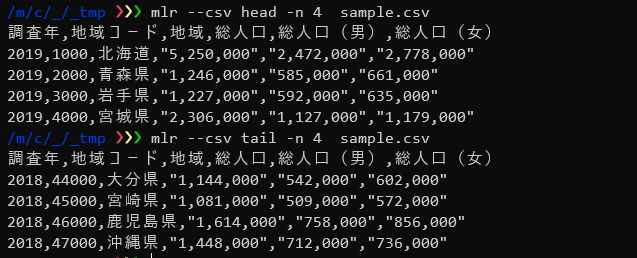
先頭行を表示したい場合はcatヴァーブの代わりにheadヴァーブを使います
-nオプションで表示する行数を指定できます。
|
1 |
$ mlr --csv head -n 4 sample.csv |
headヴァーブの代わりにtailヴァーブを使うと末尾から表示することができます。
|
1 |
$ mlr --csv tail -n 4 sample.csv |
・データ形式を変換して出力する
csvファイルを読み込みjsonファイルとして出力します。
|
1 |
$mlr --icsv --ojson cat sample.csv |

–i<input file type> –o<output file type> とオプション指定することで入力ファイル形式と出力ファイル形式を変更出来ます。
|
1 2 3 |
$ mlr --icsv --ojson cat sample.csv //csv->json $ mlr --itsv --ocsv cat sample.tsv //tsv-->csv $ mlr --icsv --opprint cat sample.csv //csv->pprint(整形された表) |
■不要なフィールド(列)の削除
cutヴァーブを使うと、出力するフィールドを指定することができます。
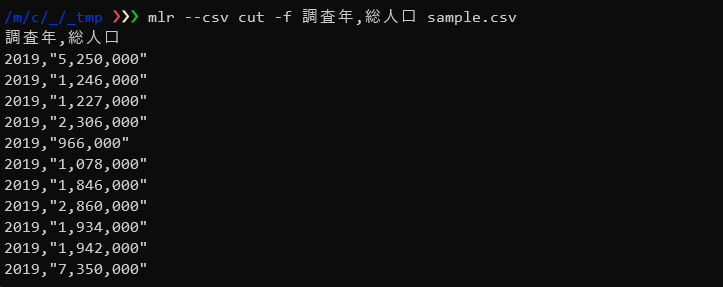
ここではサンプルデータの中から、「調査年」と「総人口」フィールドのみを出力しています。
|
1 |
mlr --csv cut -f 調査年,総人口 sample.csv |
|
1 |
$ mlr --csv cut -o -f 総人口,調査年 sample.csv |

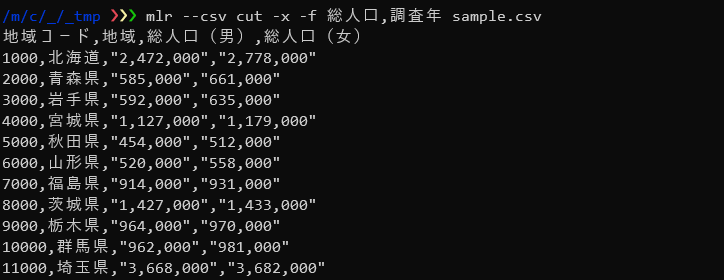
-xオプションを使うと、出力しないフィールドを指定することができます。
|
1 |
$ mlr --csv cut -x -f 総人口,調査年 sample.csv |
■データのフィルタリング
filterヴァーブを使うと、データをフィルタリングして出力することができます。
ここではサンプルデータのなかから「調査年」が2018年のデータだけをフィルタリングして出力しています。
|
1 |
$ mlr --csv filter '${調査年} == 2018' sample.csv |
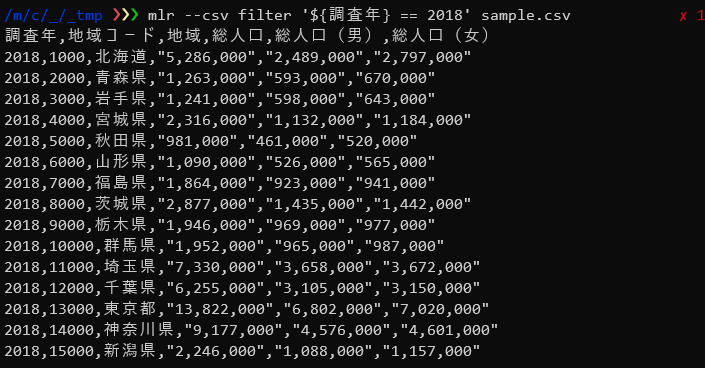
${フィールド名}で指定したフィールドの値を取り出し、フィルタの条件として指定出来ます。
filterヴァーブのステートメントでは、MillerDSLという特有のプログラミング言語を使用することができ、組み込み関数などを使って複雑な指定を行うことができます。
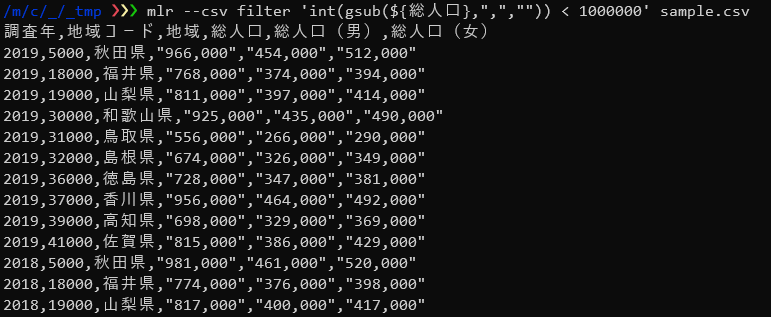
以下は、「総人口」フィールドの値からカンマを削除し数値に変換してから総人口が百万人以下のデータだけをフィルタリングしています。
|
1 |
$ mlr --csv filter 'int(gsub(${総人口},",","")) < 1000000' sample.csv |
DSLを使ったフィルタリングの詳細については「DSL filter statements」を参照してください。
■フィールドの追加
putヴァーブを使うことで、新しいフィールドを追加して出力することができます。
|
1 |
$ mlr --csv put '${新しい列} = "new!"' sample.csv |
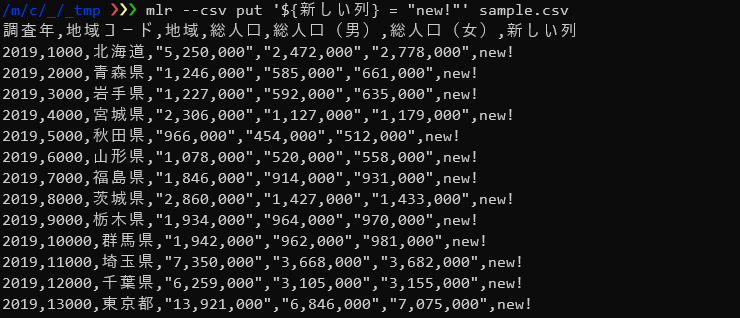
filterヴァーブ同様putヴァーブでもDSLを使って複雑な処理を行うことができます。
以下は、「総人口」と「総人口(男)」の値を数値に変換し割合を計算した後、パーセント表示へと変換した値を新たに追加した「男性割合」フィールドに収めて出力しています。
|
1 2 3 4 |
mlr --csv put ' @numAllPop = int(gsub(${総人口(男)}, ",", "")); @numMenPop = int(gsub(${総人口}, ",", "") ); ${男性割合} = fmtnum(@numAllPop / @numMenPop * 100, "%.2f") . "%";' sample.csv |
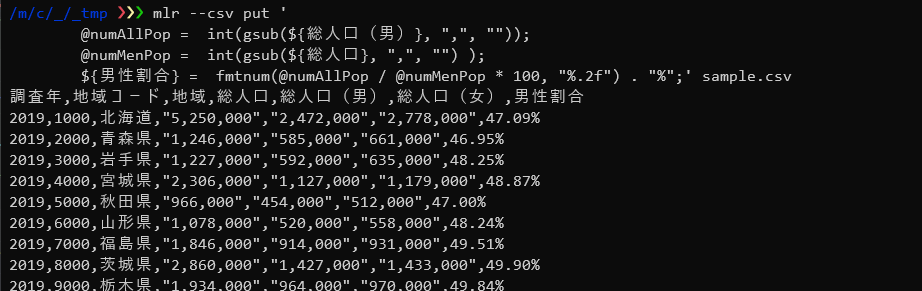
DSLを改行する場合は行末にセミコロンを付けます。
gsub関数でカンマを削除(置換)しています。
int関数で文字列を数値に変換して計算し、fmtnum関数で小数点以下2位までの出力へ変換した後、”%”文字を追加しています。文字の連結にはドット「.」演算子を使います。
putヴァーブではオプションとDSLを組み合わせることで非常に高度な処理を行うことができます。使いこなせるとデータ整形が捗るのでぜひ使ってみてください。
■ソート
sortヴァーブを使用するとデータを特定のフィールドの値でソートすることができます。
|
1 |
mlr --csv sort -f 総人口 sample.csv |
-fオプションでフィールドを指定することで、指定されたフィールドの値で並べ替えを行いますがこのままでは希望した並べ順にならない場合が多いです。
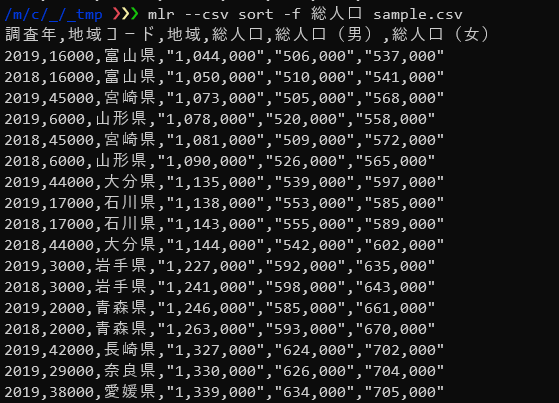
多くの場合ソートは数値の大小で並べ替えを行いたいはずです。
明示的に数値での並べ替えを行うには-n(昇順)や-nr(降順)オプションを指定します。
|
1 |
$ mlr --csv sort -nr 総人口 sample.csv |
しかし、サンプルデータではエラーが出てしまいました。
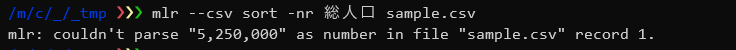
これは、サンプルデータの「総人口」の値にカンマが含まれているため文字列として読み込まれてしまっているためです。(出力したときにダブルクォーテーションマークで括られている値は文字列として認識されています)
元のデータからカンマとブルクォーテーションマークを削除して読み込み直してもよいのですが、ここでは先程紹介したputヴァーブを使って「総人口」の値を数値に修正しsortヴァーブを使って並べ替えをおこなってみます。
|
1 |
$ mlr --csv put '${総人口} = gsub(${総人口}, ",", "")' sample.csv | mlr --csv sort -nr 総人口 |
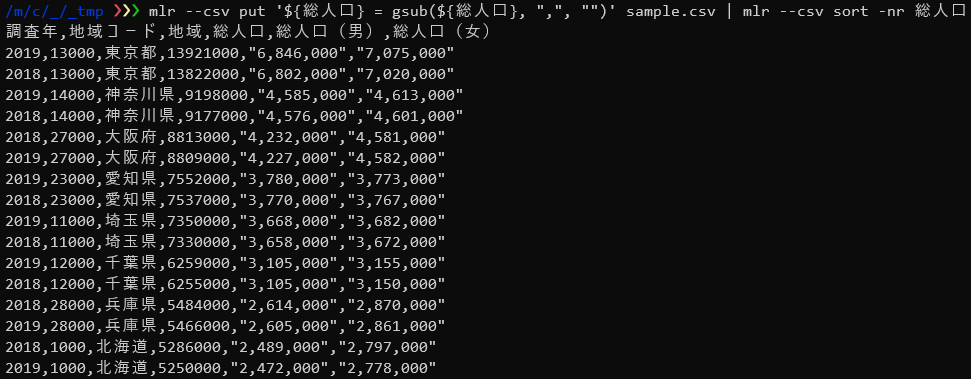
無事、総人口(降順)で並べ替えが行えました。
■結合(JOIN)
複数のデータファイルを特定のキーで結合したい場合は、joinヴァーブを使用します。
・サンプルデータ
ここでは、「地域コード」と「地域」のみをまとめたleft_data.csvと、もとのsampleデータから「地域」を除いたright_data.csvを結合し、もとのsampleデータを復元します。
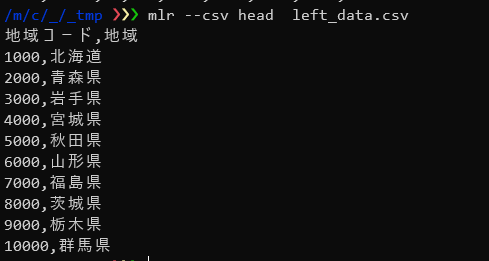
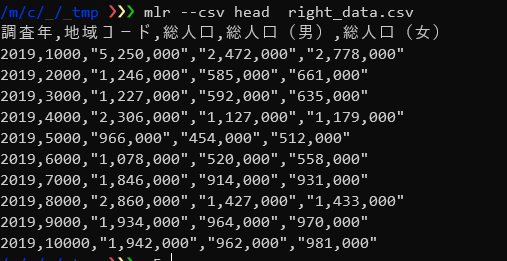
left_data.csvとright_data.csvを結合
|
1 |
mlr --csv join -j 地域コード -f left_data.csv right_data.csv |
-jオプションでキーとなるフィールド名を指定します。そのご結合するファイルを-fオプションで指定します。
joinヴァーブの時は-fオプションがフィールド名ではなく、結合対象とするファイル名を指定するオプションになるのがちょっと分かりづらいので注意です。
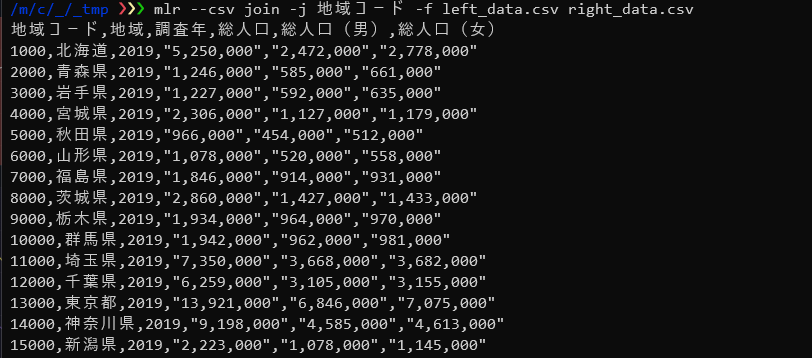
ここではシンプルな結合しか紹介しきれませんが、JOINヴァーブには多数のオプションがありそれらを駆使することで複雑な結合処理を行うことができます。詳細についてはリファレンスの「join」の項や「Questions about joins」を参照してください。
■時系列データ操作
millerでは読み込んだ値を、数値や文字列以外に日付型として扱うことができます。
そのため、時系列データをフィルタリングしたり整形するのが手軽に行うことができます。
・サンプルデータ
TimeSeriesData.csvを用いて解説します
・特定の時間以前以後でフラグを追加する
サンプルデータを読み込み、「日時」フィールドの値を元に”2022-1-25 16:00″以後のデータにtureを以前のデータにfalseをつけるフィールド「flag」を追加します。
|
1 2 3 4 |
mlr --csv put ' @t = strptime(${日時}, "%Y-%m-%d %H:%M"); @start = strptime("2022-1-25 16:00", "%Y-%m-%d %H:%M"); $flag = @t > @start' TimeSeriesData.csv |
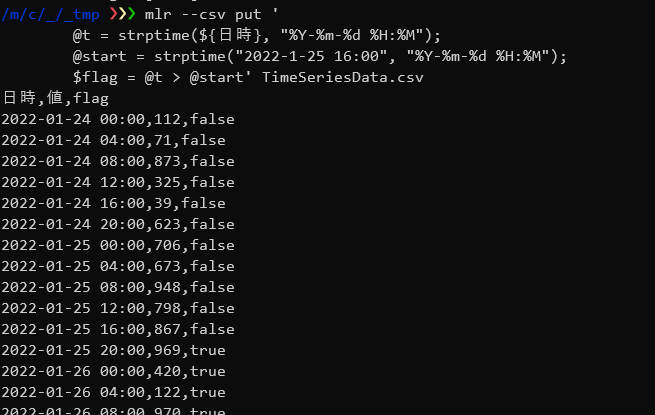
strptime関数を使ってDate型に変換して日時の比較を行っています。
・特定の時間内のデータだけ出力する
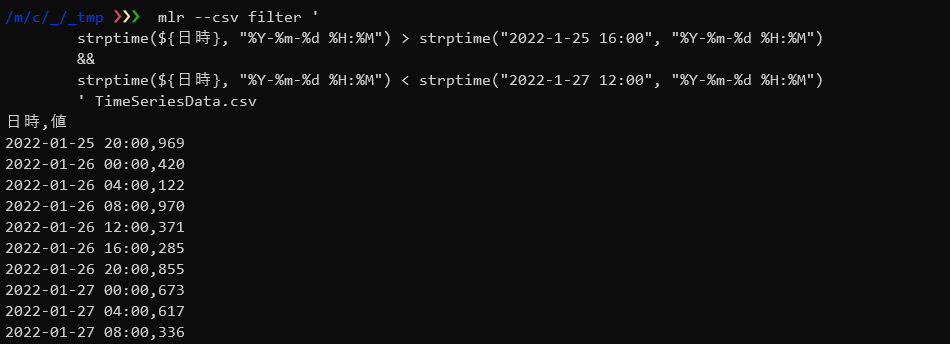
サンプルデータを読み込み、「日時」フィールドの値を元に”2022-1-25 16:00″から、”2022-1-27 12:00″までのデータを出力します。
|
1 2 3 4 5 |
$ mlr --csv filter ' strptime(${日時}, "%Y-%m-%d %H:%M") > strptime("2022-1-25 16:00", "%Y-%m-%d %H:%M") && strptime(${日時}, "%Y-%m-%d %H:%M") < strptime("2022-1-27 12:00", "%Y-%m-%d %H:%M") ' TimeSeriesData.csv |
・曜日のフィールドを追加する
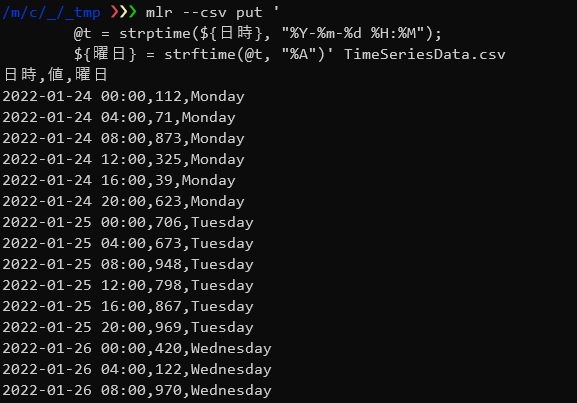
Date型に変換した値から曜日を取得し「曜日」フィールドとして追加します。
|
1 2 3 |
$ mlr --csv put ' @t = strptime(${日時}, "%Y-%m-%d %H:%M"); ${曜日} = strftime(@t, "%A")' TimeSeriesData.csv |
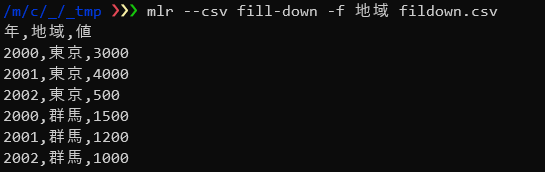
■フィールダウン
わりとよくありがちな先頭の行にしか値が入っていないタイプのデータを前行の値を元に補完します。
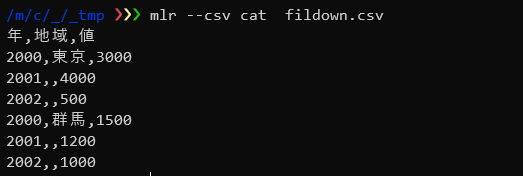
ここでは「地域」の値を前行の値を元にして埋めています。
|
1 |
mlr --csv fill-down -f 地域 fildown.csv |
■おまけ
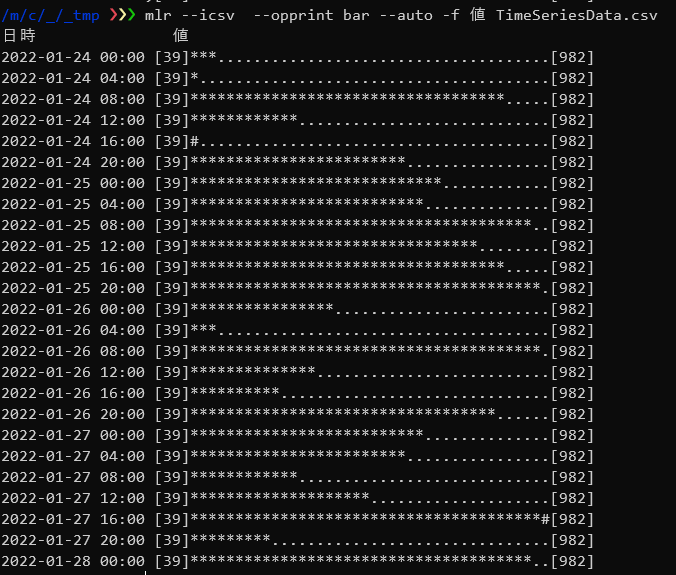
・値を棒グラフとして出力する
|
1 |
mlr --icsv --opprint bar --auto -f 値 TimeSeriesData.csv |