
【D3.js】「全ツイート履歴」からWord cloudを作ってみた。
嗜好がバレる。
自分のすべてのツイートをダウンロードできるようにしました
日本の皆さんにも「全ツイート履歴」が使えるようになりました
全ツイートのダウンロードが可能になっていたので、ダウンロードしたtweets.csvを使ってワードクラウドを作成してみました。
データセット作成
過去の全ツイートから固有名詞を抜き出して出現回数順にランキングにしたデータを作成します。
2007年から使っているわりに、累計ツイート数が10,939件と少ないのでテキスト処理系コマンドとExcelを使って行いました。ツイート数が多い場合は、以下の方法では難しいかもしれません。
まず、Windowsで処理しやすいようにS-JISに変換します。
|
1 |
$ nkf -s tweets.csv > tweets_sjis.csv |
出力したtweets_sjis.csvをExcelで読み込み、ツイート(text)だけを残して他を全て削除します。
tweets_sjis.txtをMeCabに読み込ませ形態素解析を行います。
MeCabの使い方については以下を。
MeCabのコマンドライン引数一覧とその実行例
|
1 |
$ cat tweets_sjis.txt |mecab > words.txt |
↓こんな感じのファイルが出力されます。
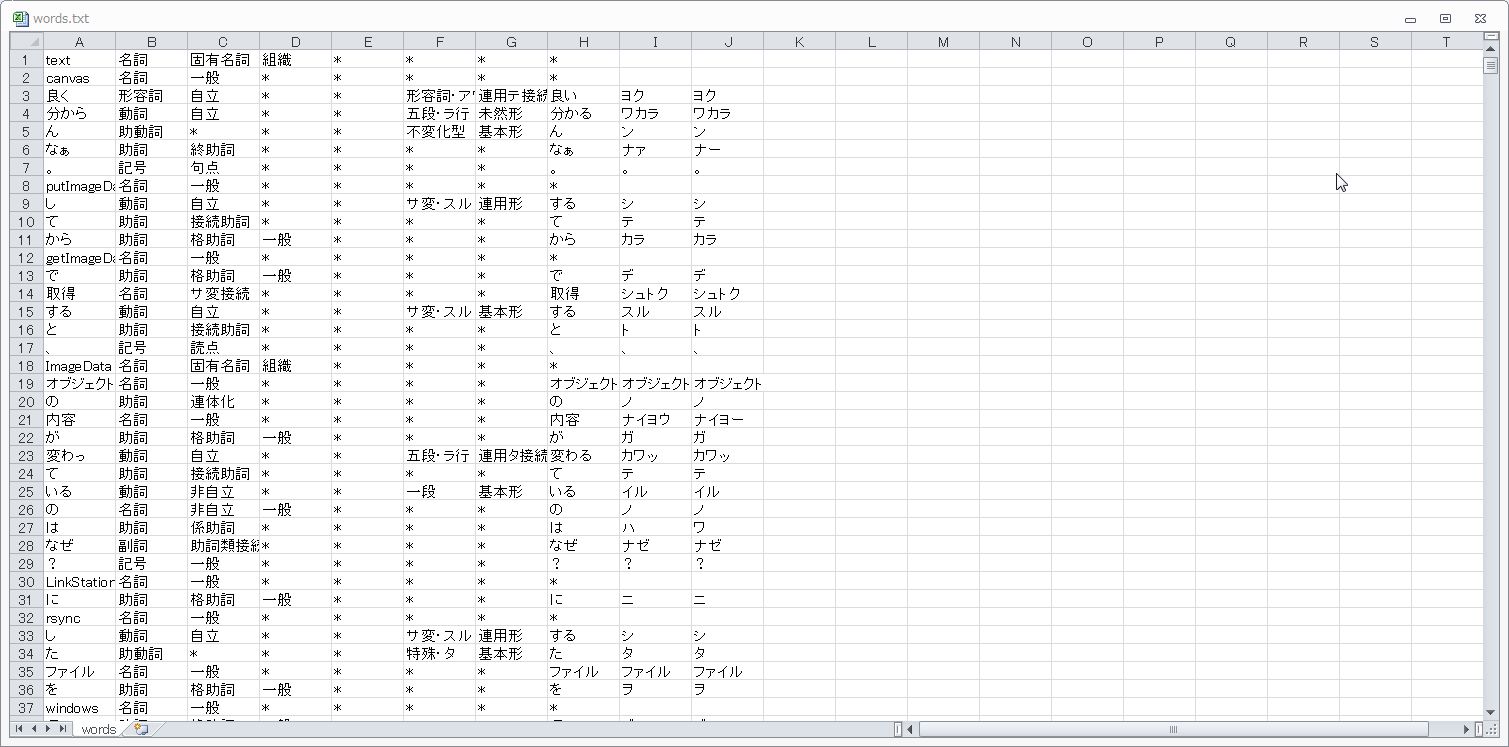
データの区切り位置とフィルタ機能を使って固有名詞のみ取り出し、単語以外を削除して別ファイル(meishi.txt)として保存します。
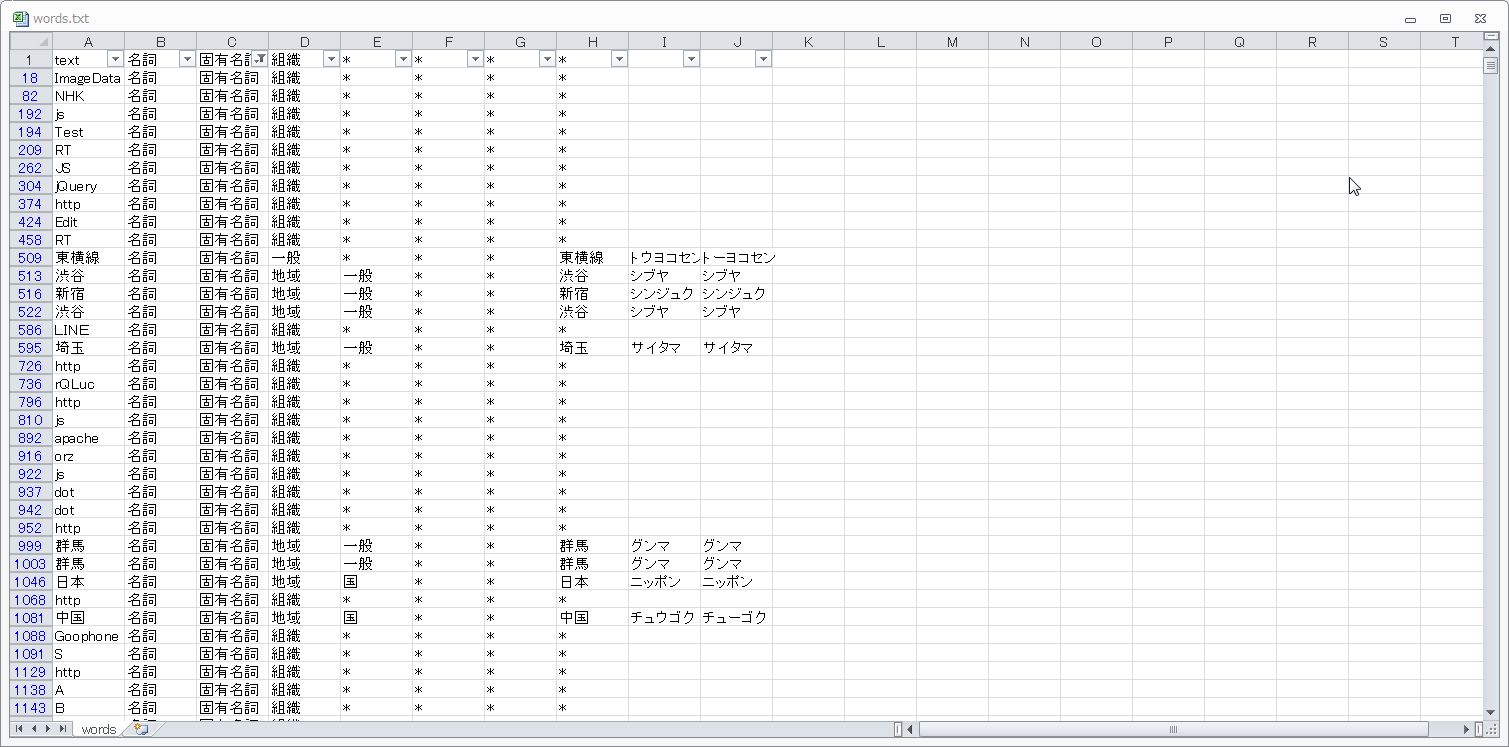
保存したファイルをソートしてユニークで絞込み重複をカウントします。
|
1 |
sort meishi.txt|uniq -c|sort /R > ranking.txt |
これで全ツイートから頻出単語の取出しが完了です。
ちなみに上位10件はこんな感じ。
|
1 2 3 4 5 6 7 8 9 10 11 |
count word 457 日本 253 orz 176 群馬 170 高崎 97 東京 64 アメリカ 63 Google 58 iPhone 55 中国 51 前橋 |
どうやら日本が大好きらしい。そして凹みまくっているようです。
このファイルをまたExcel等でcsvに変換しデータ作成作業は終了です。
ワードクラウドの表示
D3.jsとwordcludプラグインを使用してワードクラウドを作成します。
jasondavies / d3-cloud
全ての出現単語に対して処理をすると表示されるまでにかなり時間がかかるので1200件に絞っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
d3.csv(‘ranking.csv’, function(data){ var h = 800; var w = 800; data = data.splice(0, 1200); //処理wordを1200件に絞る var random = d3.random.irwinHall(2) var countMax = d3.max(data, function(d){ return d.count} ); var sizeScale = d3.scale.linear().domain([0, countMax]).range([10, 100]) var colorScale = d3.scale.category20(); var words = data.map(function(d) { return { text: d.word, size: sizeScale(d.count) //頻出カウントを文字サイズに反映 }; }); d3.layout.cloud().size([w, h]) .words(words) .rotate(function() { return Math.round(1-random()) *90; }) //ランダムに文字を90度回転 .font("Impact") .fontSize(function(d) { return d.size; }) .on("end", draw) //描画関数の読み込み .start(); //wordcloud 描画 function draw(words) { d3.select("svg") .attr({ "width": w, "height": h }) .append("g") .attr("transform", "translate(150,150)") .selectAll("text") .data(words) .enter() .append("text") .style({ "font-family": "Impact", "font-size":function(d) { return d.size + "px"; }, "fill": function(d, i) { return colorScale(i); } }) .attr({ "text-anchor":"middle", "transform": function(d) { return "translate(" + [d.x, d.y] + ")rotate(" + d.rotate + ")"; } }) .text(function(d) { return d.text; }); } }); |
“【D3.js】「全ツイート履歴」からWord cloudを作ってみた。” への1件の返信
現在コメントは受け付けていません。